Capturing Computational Environments#
There are several ways of capturing computational environments. The major ones covered in this chapter will be Package Management Systems, Binder, Virtual Machines, and Containers. Each has its pros and cons, and the most appropriate option for you will depend on the nature of your project.
They can be broadly split into two categories: those that capture only the software and its versions used in an environment (Package Management Systems), and those that replicate an entire computational environment - including the operating system and customised settings (Virtual Machines and Containers).
Another way these can be split is by how the reproduced research is presented to the reproducer. Using Binder or a Virtual Machine creates a much more graphical, GUI-type result. In contrast, the outputs of Containers and Package Management Systems are more easily interacted with via the command line.
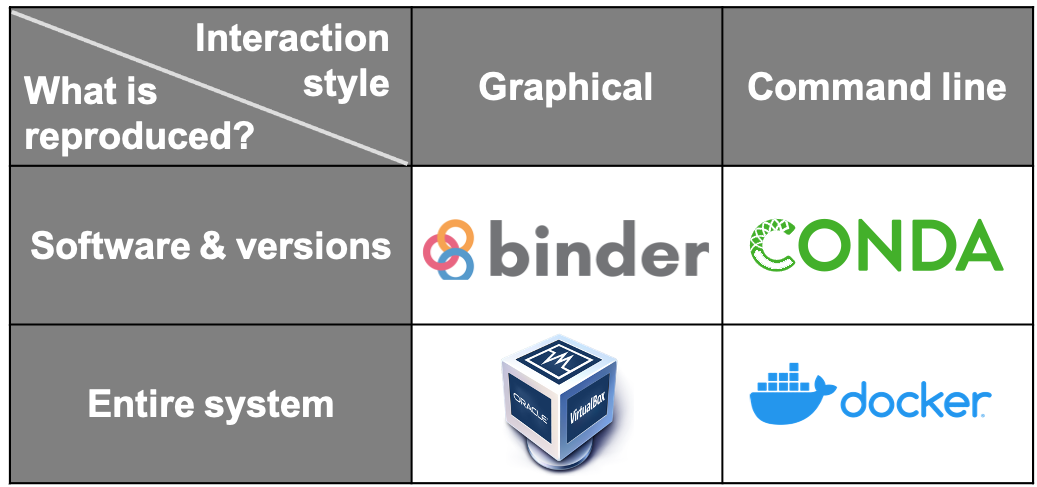
Fig. 56 Ways of capturing computational environments#
A brief description of each of these tools is given below
Package Management Systems#
Package Management Systems [def] are tools used to install and keep track of the software (and critically versions of software) used on a system and can export files specifying these required software packages/versions. The files can be shared with others who can use them to replicate the environment, either manually or via their Package Management Systems.
Binder#
Binder [def] is a service which generates fully-functioning versions of projects from a git repository and serves them on the cloud. These “binderized” projects can be accessed and interacted with by others via a web browser. In order to do this, Binder requires that the software (and, optionally, versions) required to run the project are specified. Users can make use of Package Management Systems or Dockerfiles (discussed in the Containers sections) to do this if they so desire.
Virtual Machines#
Virtual Machines [def] are simulated computers. A user can make a “virtual” computer very easily, specifying the operating system they want it to have, among other features, and run it like any other app. Within the app will be the desktop, file system, default software libraries, and other features of the specified machine. These can be interacted with as if it was a real computer. Virtual Machines can be easily replicated and shared. This allows researchers to create Virtual Machines, perform their research on them, and then save their state along with their files, settings and outputs. They can then distribute these as a fully-functioning project.
Containers#
Containers [def] offer many of the same benefits as Virtual Machines. They essentially act as entirely separate machines which can contain their own files, software and settings.
The difference is that Virtual Machines include an entire operating system along with all the associated software that is typically packaged with it - regardless of whether the project makes use of that associated software. Containers only contain the software and files explicitly defined within them in order to run the project they contain. This makes them far more lightweight than Virtual Machines.
Containers are particularly useful if projects need to run on high-performance computing environments. Since they already contain all the necessary software, they save having to install anything on an unfamiliar system where the researcher may not have the required permissions to do so.